One of the benefits of coming to a greenfield job – like when I joined Mind Candy two years ago – was that you can jump several technological steps ahead as you don’t have any legacy to deal with. Essentially we could build from scratch based on lessons learned from traditional data architecture. One of the main ones was to establish a real-time path right away to avoid having to shoehorn it in afterwards. Another was to avoid physical hardware. And the most important one was to hold off on Hadoop as long as possible.
The last one might seem surprising, isn’t Hadoop the centre-piece of a data architecture? Unfortunately it creates a lots of admin overhead and it might be a full person’s (or more) workload to maintain. Not ideal in a small company where people resources are limited. AWS S3 can fulfil most of the storage function but requires no maintenance and is largely fast enough. Also while HDFS is important and will probably come back for us soon, MR1 or YARN is just not – there are better and more advanced execution systems that can use HDFS and we used one of those: Mesos.
Mesos is a universal execution engine for job and resource distribution. Unlike YARN it can not only run Spark but also Cassandra, Kafka, Docker containers and recently also HDFS. That works because Mesos just offers resources and let the framework handle the starting and management of the jobs. This finally breaks the link between framework and execution engine: in Mesos you can run not only different frameworks but different versions of the same framework. No more waiting for your infrastructure to upgrade to the latest Hadoop or Spark version, you can run it right now even when all your other jobs run on older versions. Combine that with a robust architecture and simple upgrading and Mesos can easily be seen as the successor to YARN (for more details on why Mesos beats Yarn, see Dean Wampler’s talk from Strata).
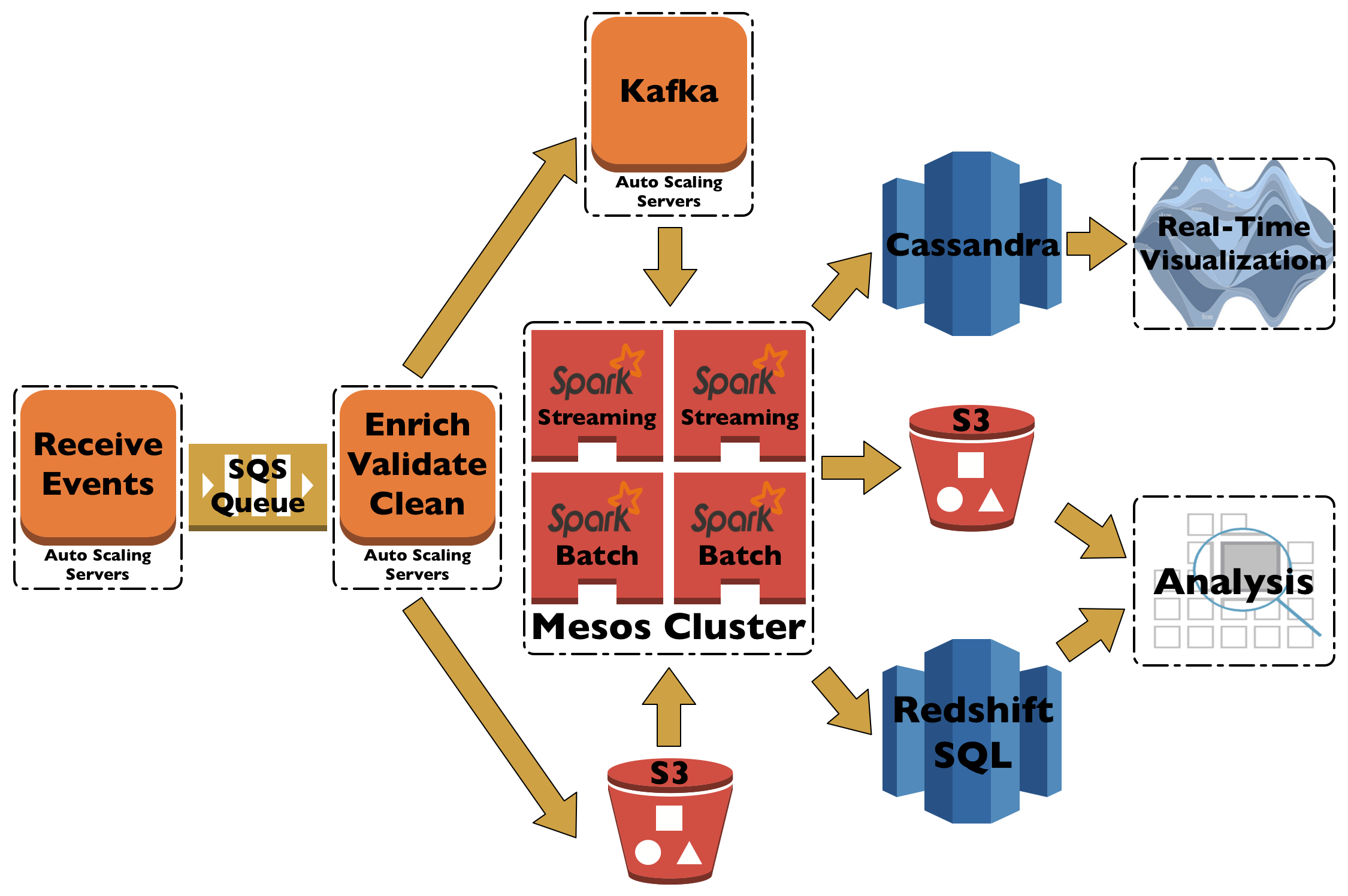
For the real-time path the obvious processing solution is Spark Streaming (so we have a simpler code base) running on Mesos with Kafka to feed data in and with Cassandra to store the results. You now have a so-called SMACK stack (Spark Mesos Apache Cassandra Kafka) for data processing which the Mesos folks call Mesosphere Infinity for some reason (aka marketing).
The last bit of a data architecture is the SQL engine. Traditionally this was Hive but we all know Hive is slow. While there are several open-source solutions out there that improve on good old Hive (Impala, Spark SQL) in the end we decided on AWS Redshift. It’s a column-oriented SQL-based data warehouse with PostgreSQL interface which fulfils most of the data analysis and data science needs while being reasonably fast and relatively easy to maintain with few people.
The resulting architecture looks like the above picture. We have an event receiver and a enricher/validate/cleaner, which were written in-house in Scala/Akka and are relatively simple programs using AWS SQS as a transport channel. The data is then send to Kafka and S3. Spark uses data straight from S3 to aggregate and put the processed data back into either Redshift or S3. On the real-time side of things we have Kafka going into Spark Streaming with an output into Cassandra.